HierVST: Hierarchical Adaptive Zero-shot Voice Style Transfer
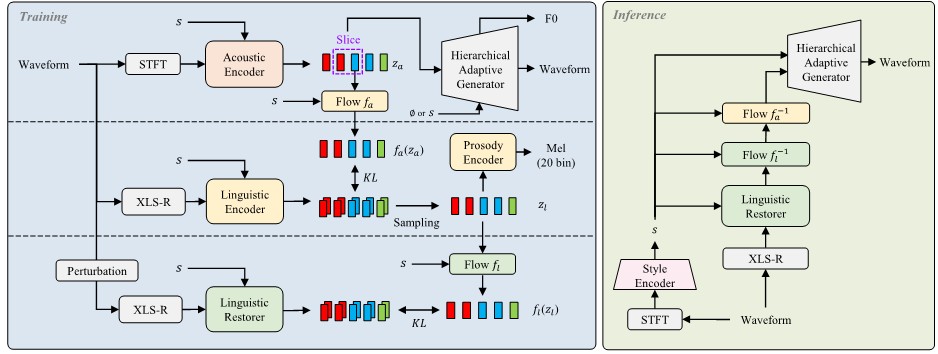 Overall framework of HierVST
Overall framework of HierVST
Overall framework of HierVSTDespite rapid progress in the voice style transfer (VST) field, recent zero-shot VST systems still lack the ability to transfer the voice style of a novel speaker. In this paper, we present HierVST, a hierarchical adaptive end-to-end zero-shot VST model. Without any text transcripts, we only use the speech dataset to train the model by utilizing hierarchical variational inference and self-supervised representation. In addition, we adopt a hierarchical adaptive generator that generates the pitch representation and waveform audio sequentially. Moreover, we utilize unconditional generation to improve the speaker-relative acoustic capacity in the acoustic representation. With a hierarchical adaptive structure, the model can adapt to a novel voice style and convert speech progressively. The experimental results demonstrate that our method outperforms other VST models in zero-shot VST scenarios.
We compare HierVST with several Voice Conversion models as:
1. AutoVC [K. Qian et al., 2019] : [Official Demo page]
2. VoiceMixer [S.-H. Lee et al., 2021]: [Official Demo page]
3. DiffVC [V. Popov et al., 2022]: [Official Demo page]
4. Speech Resynthesis [A. Polyak et al., 2021]: [Official Demo page]
5. YourTTS [E. Casanova et al., 2022]: [Official Demo page]
All speakers are seen during training
| Source Speaker | Target Speaker | Converted | ||
|---|---|---|---|---|
GT ( 159 ) |
GT ( 16 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( 374 ) |
GT ( 1607 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( 1571 ) |
GT ( 3699 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( 1638 ) |
GT ( 3440 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( 3526 ) |
GT ( 159 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( 159 ) |
GT ( 16 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
All speakers are unseen during training
| Source Speaker | Target Speaker | Converted | ||
|---|---|---|---|---|
GT ( p226 ) |
GT ( p238 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( p228 ) |
GT ( p233 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( p233 ) |
GT ( p227 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( p240 ) |
GT ( p236 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
||
GT ( p241 ) |
GT ( p232 ) |
AutoVC |
VoiceMixer |
DiffVC |
Speech Resynthesis |
YourTTS |
HierVST (Ours) |
We fine-tune the HierVST with only a single sample. Iter. denotes the fine-tuning iteration.
| Source Speaker | Target Speaker | Converted | ||
|---|---|---|---|---|
GT ( p246 ) |
GT ( p240 ) |
Zero-shot |
100 iter. |
300 iter. |
500 iter. |
1000 iter. |
1500 iter. |
||
GT ( p230 ) |
GT ( p237 ) |
Zero-shot |
100 iter. |
300 iter. |
500 iter. |
1000 iter. |
1500 iter. |
||
GT ( p237 ) |
GT ( p246 ) |
Zero-shot |
100 iter. |
300 iter. |
500 iter. |
1000 iter. |
1500 iter. |
puncond denotes the unconditional generation ratio during training.
PD: Prosody Distillation
HVAE: Hierarchical Variational Autoencoder
HAG: Hierarchical Adaptive Generator
| Source Speaker | Target Speaker | Converted | ||
|---|---|---|---|---|
GT ( p246 ) |
GT ( p240 ) |
HierVST (puncond=0) |
||
HierVST (puncond=0.1) |
HierVST (puncond=0.2) |
HierVST (puncond=0.5) |
||
w.o PD |
w.o PD & HVAE |
w.o PD & HVAE & HAG |
Unseen language from CSS10 multi-lingual dataset
| Source Speaker | Target Speaker | Converted | |
|---|---|---|---|
French |
Hungarian |
HierVST |
|
French |
Greek |
HierVST |
| Source Speaker | Target Speaker | Converted | |
|---|---|---|---|
Finnish |
Dutch |
HierVST |
|
Finnish |
Russsian |
HierVST |
| Source Speaker | Target Speaker | Converted | |
|---|---|---|---|
Russian |
Dutch |
HierVST |
|
Russian |
French |
HierVST |
| Source Speaker | Target Speaker | Converted | |
|---|---|---|---|
Spanish |
French |
HierVST |
|
Spanish |
Russian |
HierVST |
| Source Speaker | Target Speaker | Converted | |
|---|---|---|---|
German |
French |
HierVST |
|
German |
Dutch |
HierVST |